两年前跟着视频学了一次,但当时感觉学的比较糙,最近准备重新系统地学习一遍,顺便记录一些笔记。由于时间有限,这次主要跟着这位大佬的blog来学习:南大软分课程笔记
01 介绍
Sound and Complete
莱斯定理 指出对于所有非平凡的程序性质(即某个性质适用于一些程序,但是不适用于另一些程序),判断某个程序是否具备这个性质是不可判定的。他揭示了许多程序分析任务(如分析程序的行为、程序的正确性、程序是否会终止等)都无法通过算法来完全解决。
完美的静态分析是即满足Soundness(无漏报)又满足Completeness(无误报)的分析。然而根据莱斯定理,任何非平凡的程序性质都不可判定,因此不存在既Sound又Complete的静态分析。
Sound 是指分析结果绝对没有遗漏任何真实存在的程序行为或错误。这意味着,如果程序在实际执行中有某个问题必然会发生,Sound 的分析器一定会报告它(绝不漏报),但可能会包含一些实际上不会发生的警告(即可能有误报)。
def check_value(x):
y = 10
if x > 100:
y = 0 # 只有当 x > 100 时,y 才会是 0
else:
y = 5
result = 100 / y # 这里有潜在的除零风险
在上面的例子中,如果静态分析器是sound的,它会报告除零风险,因为当 x > 100 时,y 可能为 0。即使在实际运行中,x 可能永远不会大于 100,分析器仍然会报告这个风险,以确保没有遗漏任何可能的错误。
Complete 是指分析结果绝对没有误报任何不存在的程序行为或错误。这意味着,如果分析是complete的,那么它报告的所有问题在程序实际执行中都必然会发生(无误报),但可能会遗漏一些真实存在的问题(即可能有漏报)。 同样在上面的例子中,如果静态分析器是complete的,它可能不会报告除零风险,因为在实际运行中,x 可能永远不会大于 100,从而 y 永远不会为 0。这样,分析器确保没有误报任何不存在的错误,但可能会遗漏一些真实存在的问题。

Sound and Complete
Abstraction & Over-approximation
大多数静态分析都可以使用abstraction和over-approximation这两个词进行概括,后者又可以划分为transfer function和control flows。
Abstraction,将变量从concrete domain映射到abstract domain。程序在运行时,变量的值有无穷种可能(例如具体的整数),如果分析工具要追踪每一个具体的值,就可能会导致状态爆炸。所以,我们需要忽略一些细节,只关注关键特征。
Concrete domain to abstract domain, contrains five symbols: + - 0 ⊤ ⊥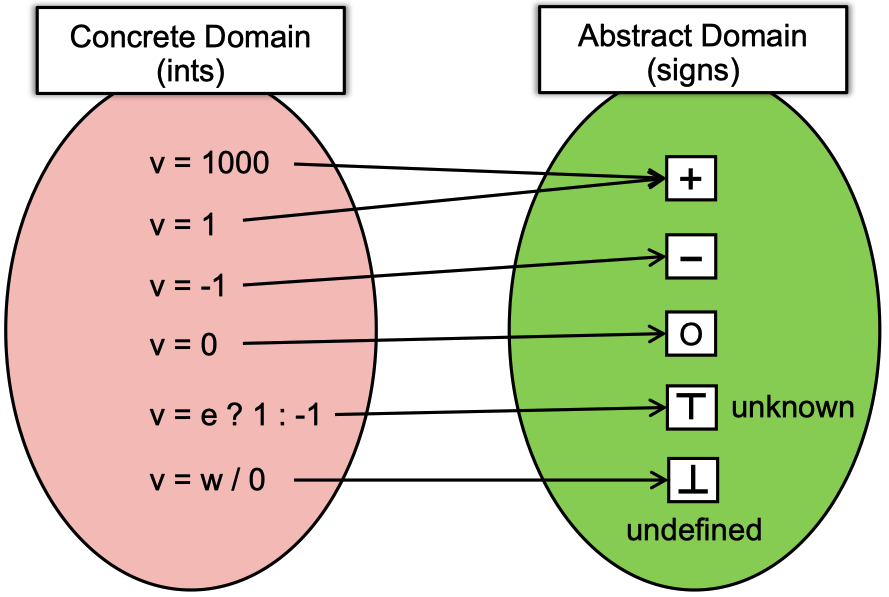
Over-approximation,是为了之前讨论的soundness的实现手段。因为我们做了abtraction,丢失了一些细节,导致很多时候我们无法精确判断,为了确保sound,在遇到不确定的情况时需要涵盖所有的可能性。上面图片中的v = e ? 1 : -1 因为我们不清楚v的值是正还是负还是0,所以为了安全起见,要把所有的结果都算进来,即Top。
- Transfer Function,指分析器如何处理每一行代码的逻辑。其任务就是给定输入状态,计算这一行代码输出后的状态。
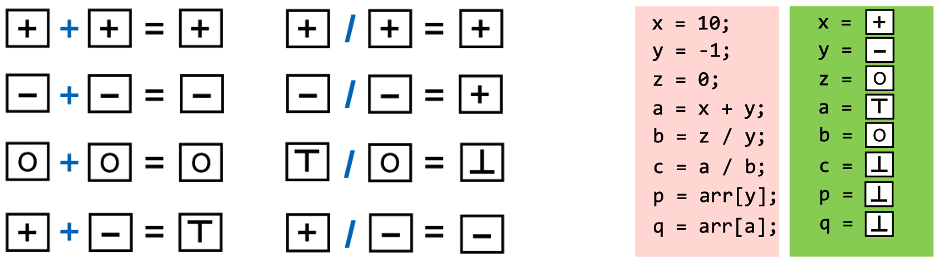
Transfer Function
- Control Flows,指分析器如何处理
if/else,while等分支结构。在实际场景中进行控制流相关的静态分析时,由于无枚举所有的路径,我们通常采用flow merging来进行处理。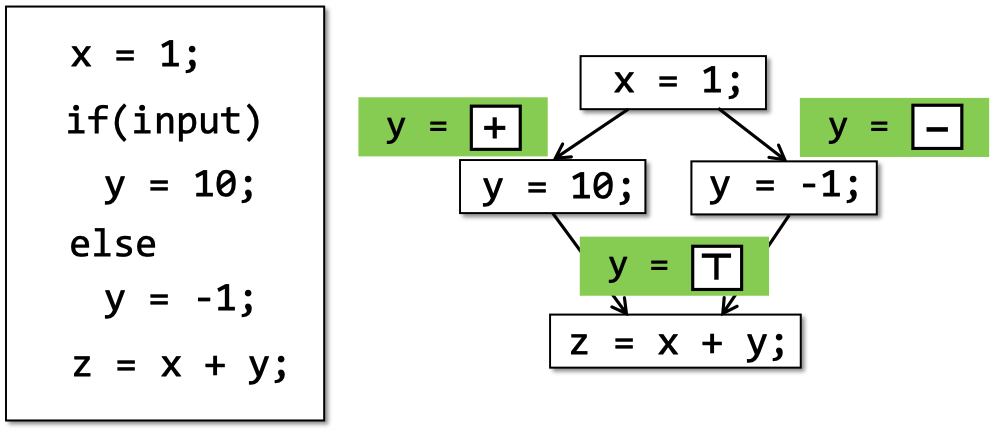
Control Flows
02 中间语言
前言
为什么需要IR?
- 高级语言包含大量语法糖(像三元运算符,多种循环写法等),这对分析器来说很复杂,但是使用IR可以把复杂的操作拆分成简单的指令,便于后续的分析。
- 在IR上展开分析可以服用后端这些算法,只需要对不同的语言写前端进行解析即可。
- 便于构建CFG,而静态分析中的核心算法都是在CFG上跑的。
Compilers and Static Analyzers
从下图可以看到,编译通常包括词法分析、语法分析、语义分析等过程,最终生成机器码。静态分析使用的是Translator生成的IR。
Compile Stage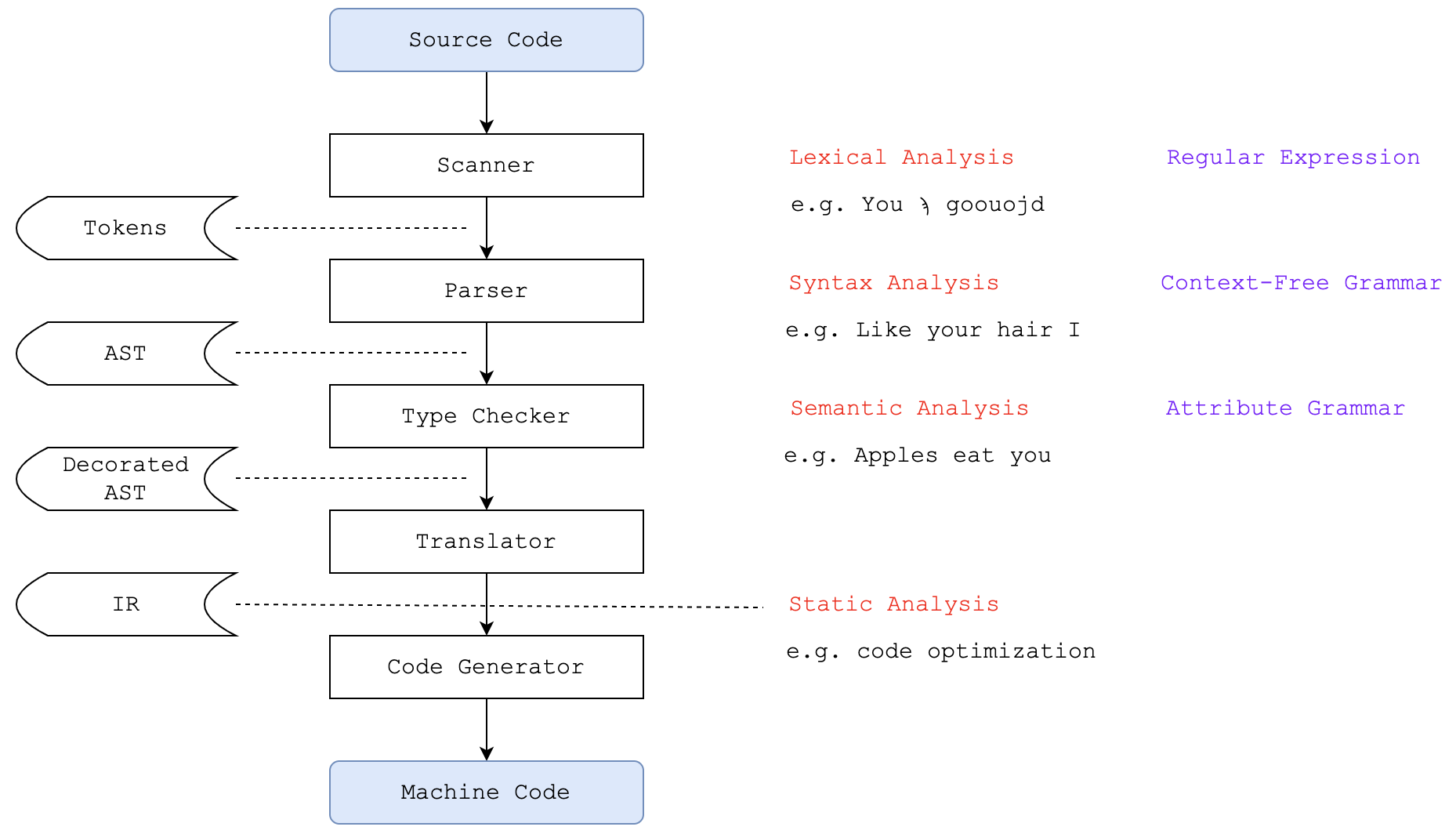
do i = i + 1;
while(a[i] < v)
对应的AST如下:
对应的IR如下:
1: i = i + 1
2: t1 = a[i]
3: if t1 < v goto 1
可以发现IR要简洁很多,总结一下,AST和IR的各自特点是:
| AST | IR |
|---|---|
| 层次较高,更接近语法结构 | 层次较低,更接近机器码 |
| 通常是和语言相关的 | 通常是语言无关的 |
| 适合用于快速类型检查 | 通常是简洁而统一的 |
| 缺乏控制流信息 | 包含控制流信息 |
| - | 通常用作静态分析的基础 |
三地址码
三地址码(3-Address Code)是一种常见的IR表示形式,指的是每条3AC指令至多可以包含三种地址(通常是两个源操作数一个目标操作数):变量名、常量以及编译器生成的临时变量,并且要求在一条指令的右边最多只有一个操作符。下面是一些常见的3AC形式:
x = y bop z
x = uop y
x = y
goto L
if x goto L
if x rop y goto L
静态单赋值
SSA不是一种指令格式,而是一种对变量的使用约束,它要求所有赋值操作的被赋值变量都需要有一个独特的名字。每个定义都会有一个新名字,这个新名字可以应用在后续的分析中,每个变量都有一个定义。下面是一个SSA的示例:
3AC: SSA:
p = a + b p1 = a + b
q = p - c q1 = p1 - c
p = q * d p2 = q1 * d
p = e - p p3 = e - p2
q = p + q q2 = p3 + q1
有时,某个变量可能受到条件分支影响,处于控制流汇聚的位置(control flow merges),此时就需要使用phi函数来处理,如下图所示:
SSA control flow merge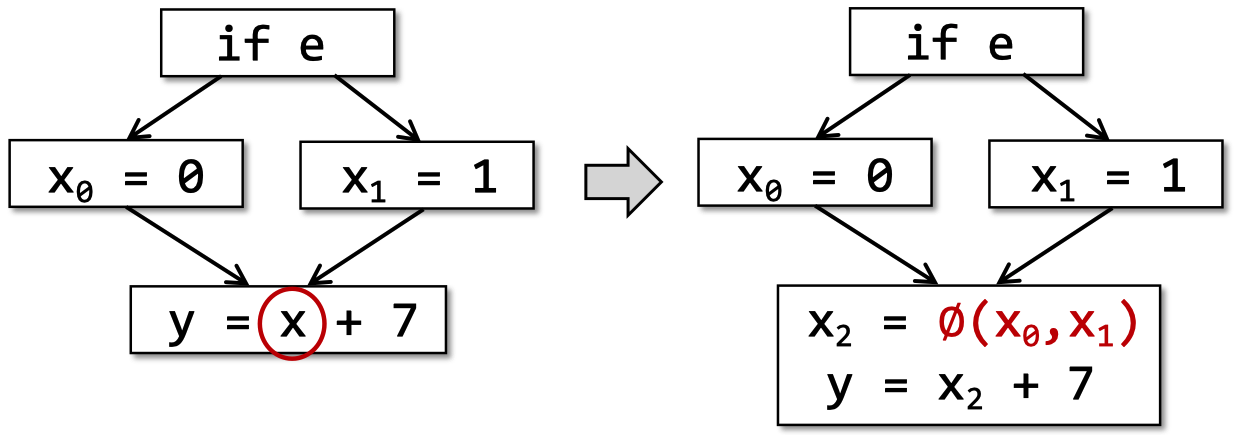
Control Flow Analysis
控制流分析通常是指建立CFG,CFG是静态分析的基础结构,他的每个节点可以是一个3AC,也可以是一个基本块,后者更为常见。下图就是输入是目标程序的3AC输出是其对应的CFG。
3AC to CFG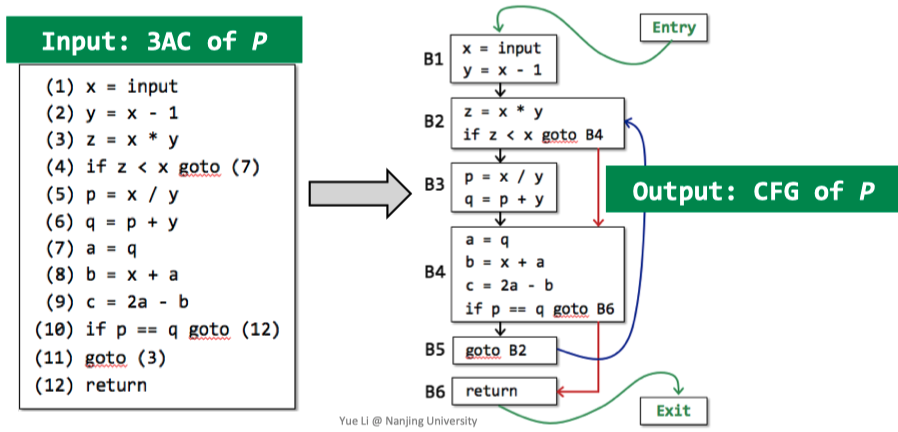
基本块(BB)是指一个连续的、最长的3AC序列,该序列有以下两个特性:
- 控制流只能从该序列的起始指令进入;
- 控制流只能从该序列的最后一条指令退出。
划分BB的算法:
- 确定3AC指令中的leaders,leaders即具有下述特性的指令:
- 3AC序列中的第一条指令
- 所有有条件跳转或无条件跳转的所有目标指令
- 所有有条件跳转或无条件跳转后面的下一条指令
- 划分BB,BB包含leader指令以及后面紧邻的所有飞leader指令
构建CFG:
- CFG的节点均为BB
- BB_a 到 BB_b 在下述两种情况下会建立有向边:
- a到b有一个有条件或无条件跳转
- b是a后面的紧邻BB并且a的最后一条指令不是无条件跳转
- 将原来3AC序列中的所有
跳转到某指令标签处改为跳转到某基本块处 - 通常会在CFG的开头和结尾添加两个虚拟节点,
Entry和Exit
03 数据流分析应用 一
前言
数据流分析就是在程序不运行的情况下,通过数学推导,预测程序运行时数据行为的技术。他研究的问题是:
- How data flows on CFG?
- How application-specific data flows the nodes(BB/inst)and edges(control flows) of CFG (a program)? 对于CFG中的nodes,我们需要使用transfer function进行处理;对于edges,我们需要处理控制流,例如在merge点对不同分支的结果进行union处理。不同的数据流分析应用有着不同的数据抽象和不同的流近似安全策略,即不同的transfer function和control flow handling。
数据流分析中的输入和输出状态:
- 每个IR语句的执行将一个输入状态 ($IN$)转换成一个新的输出状态($OUT$)
- 某个IR语句的输入(输出)状态与该语句之前(之后)的program point关联
在数据流分析应用中,我们通常将每个program point与一个data-flow value关联,这个data-flow value代表了在该点上可以观察到的所有可能的程序状态的抽象集合。对于一个应用来说,所有可能的data-flow values构成的集合成为该应用的domain。
数据流分析的目标就是解开$IN$ 和 $OUT$的方程组(解约束集合),在这个过程中,如果遇到不确定的情况(如分支汇合),我们必须选择那个最正确的值(safe-approximation contrains over-approximation and under-approximation),并最终让整个系统的数据状态稳定下来(找到解,达到fixed-point)。
- 约束集合,在数据流分析中,每一行代码s都有两个未知数 $IN[s]$ 和 $OUT[s]$,这里的约束就是限制 $IN$ 和 $OUT$ 之间关系的方程组。
- 找到解就是说分析到达了不动点,就是在某一次计算之后所有program point的data-flow value都不发生变化。
- safe-approximation是说现实中的程序都是很复杂的,我们一般很难得到精确解,这里需要做出妥协,来做出近似,得到安全近似解。
Reaching Definitions Analysis
什么是defination:在程序分析中任何给变量赋值的语句都叫定值,如x=5, y=x+1等。
什么是定义可达性?
A defination d at program point p reaches a point q if there is a path from p to q that d is not killed along that path. 不考虑具体的执行路径,如果有一条路径能从赋值语句d(如第一行x=5)到达语句u(如第十行print x),且中间没有其他语句重新给x赋值,我们就说第一行的定值d到达了第十行。
Data Abstraction 对于定义可达性分析的来说,数据流中的值是一个程序中的所有变量的定义(的指令位置),它们可以用bit vector来表示,第i个变量使用第i个bit表示。在program point p处,$vector[i]=1$ 当且仅当第i行的变量定义能够到达p。
Transfer Function 该BB流出的定义 = 该BB新生成的定义 + 其他BB传入的且没有被杀死的定义 $$OUT[B] = Gen_B \cup (IN[B] - Kill_B)$$
Control Flows 当多条路径合并时,我们需要知道的是 有没有一种可能,这个定义能到达这里,所以RDA是一个may Analysis,这里使用并集合并流入的结果
$$IN[B] = \bigcup_{P \in preds(B)} OUT[P]$$
Definition gen and kill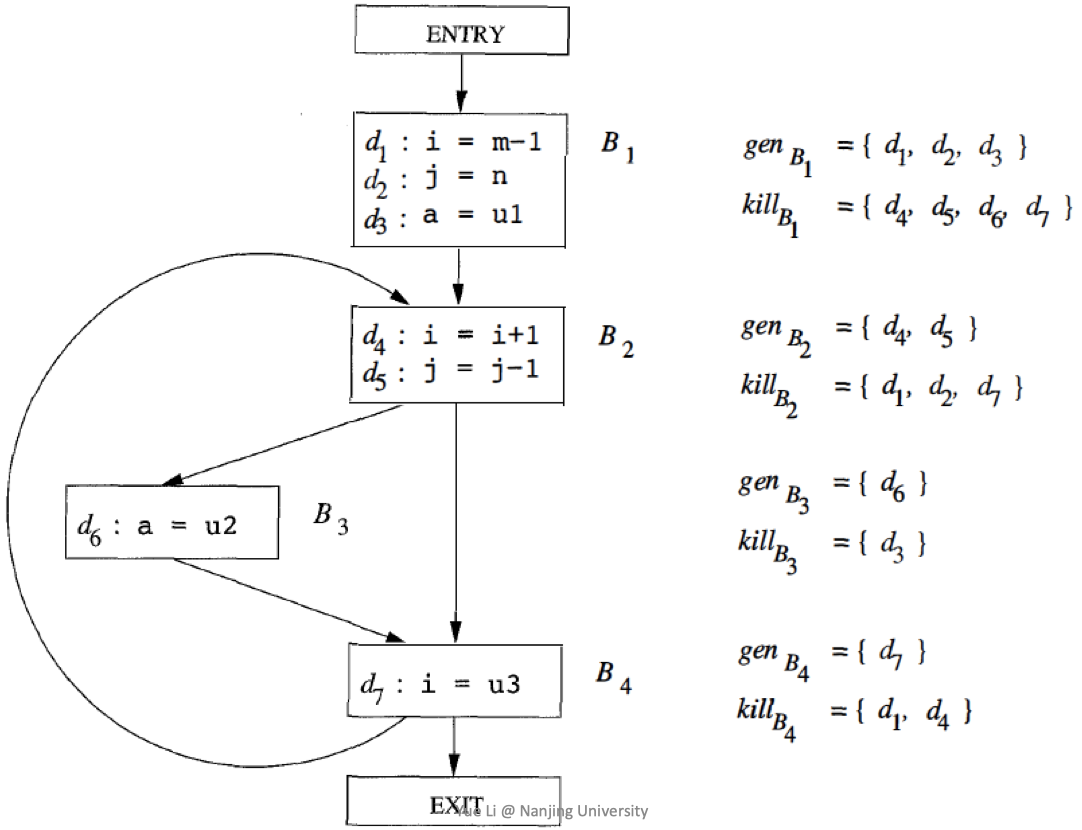

Reaching defination analysis algorithm
为什么RDA这个算法一定会停止?
- 有界性,一个程序中的definations是有限的,即bit vector的长度是有限的
- 单调性,$OUT[B]$只与$IN[B]$有关,并且要大于等于$IN[B]$,但是$IN[B] = \bigcup OUT[P]$,因此每个循环后的$IN[B]$一定不会减少
该算法是单调递增的,并且有一个上界(bit vector全部置1),因此最终一定会停止。
下面是一个RDA算法的示例,除了初始化过程外,这个分析进行了三轮。第三轮中,bit vector没有发生变化,循环终止。最终得到的不同program point处的bit vector就是定义可达性的分析结果。
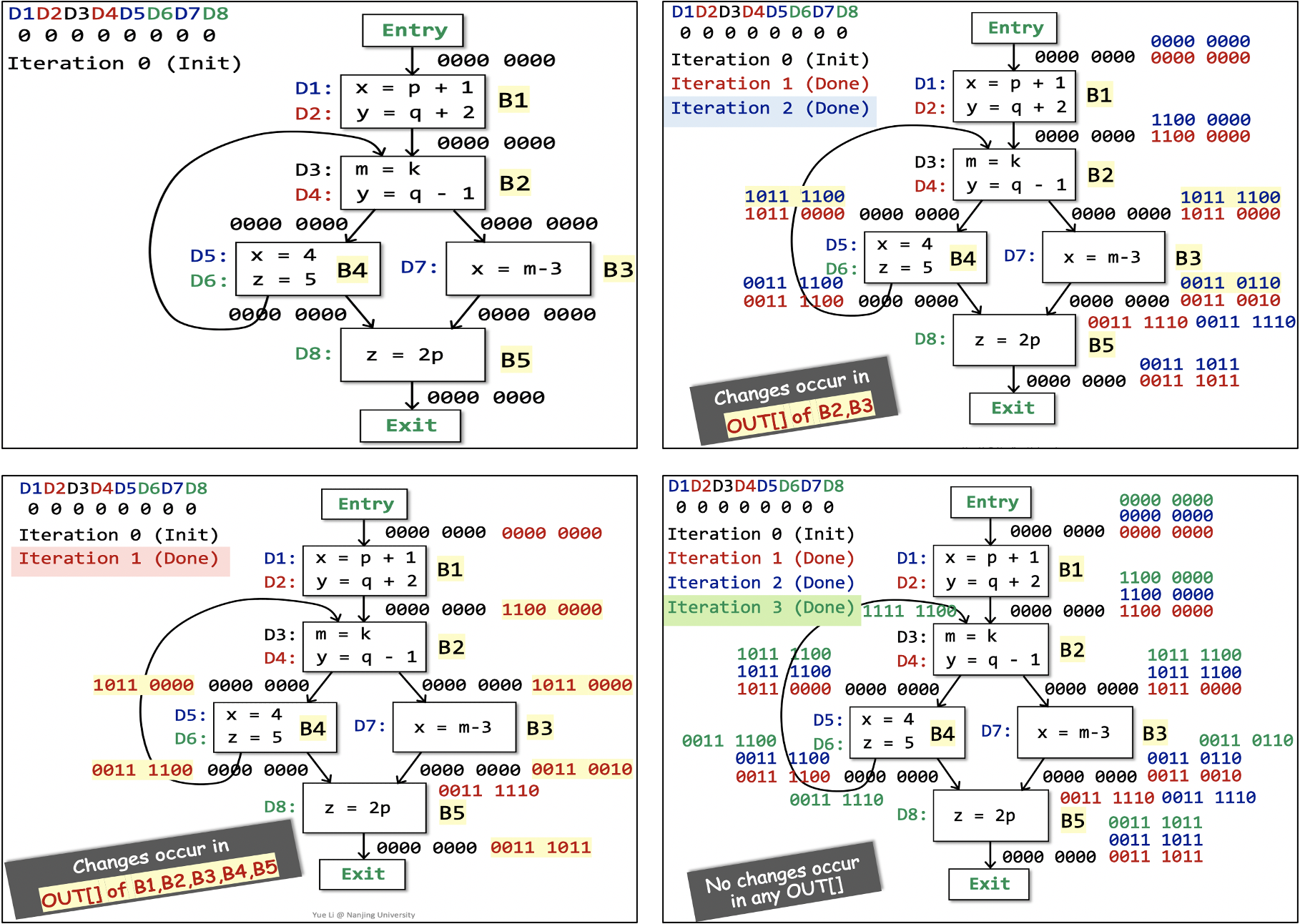
Reaching defination analysis example
RDA这个算法能用来做什么呢?
- 未初始化变量检测,我们在程序入口处为所有变量引入一个dummy defination($d_{undef}$),如果在用
print x的地方RDA发现$d_{undef}$到达此处,就可以报错,“Warning: Variable ‘x’ may be used uninitialized.” - 循环不变量外提,循环里有一句 x = y + z,RDA 发现,到达这行代码的 y 和 z 的定义,全部都在循环外面,这说明 y 和 z 在循环里根本没变过!编译器可以把这行计算提到循环外面去,避免每次循环都算一遍。