我也不知道为什么突然学了强化学习.
Basic Concepts
Grid Exmaple
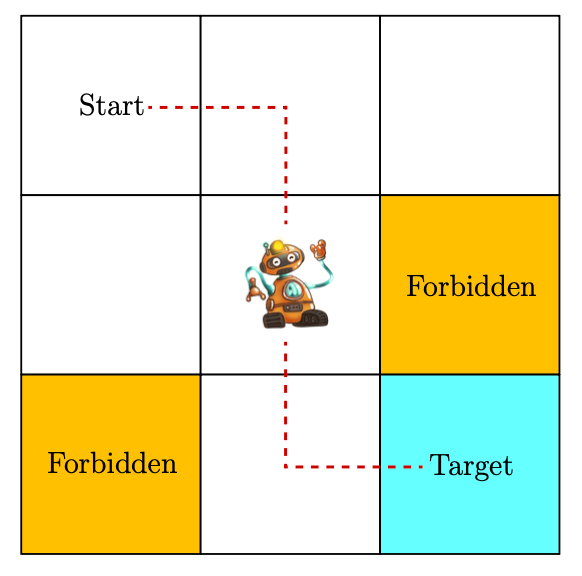
如下图所示, 一个agent在格子地图上移动个,每次一栋一格,目标就是去到target那里. accessible 是指可以进入的格子,forbidden是指不能进入或者进入会有惩罚的格子,target就是目标格子. 在这个任务中,我们的目标就是来选择一个好的策略,他能够保证无论我们从哪个格子开始都能够到达target,但是这里的 Grid Example好 是不唯一的,可以是不路过forbidden,不走不必要的弯路,不与地图的边界相撞等等. 这个任务的难点在与agent是没有预先获得环境的信息的,他需要通过尝试和犯错误来找到一个好的策略.
State and Action
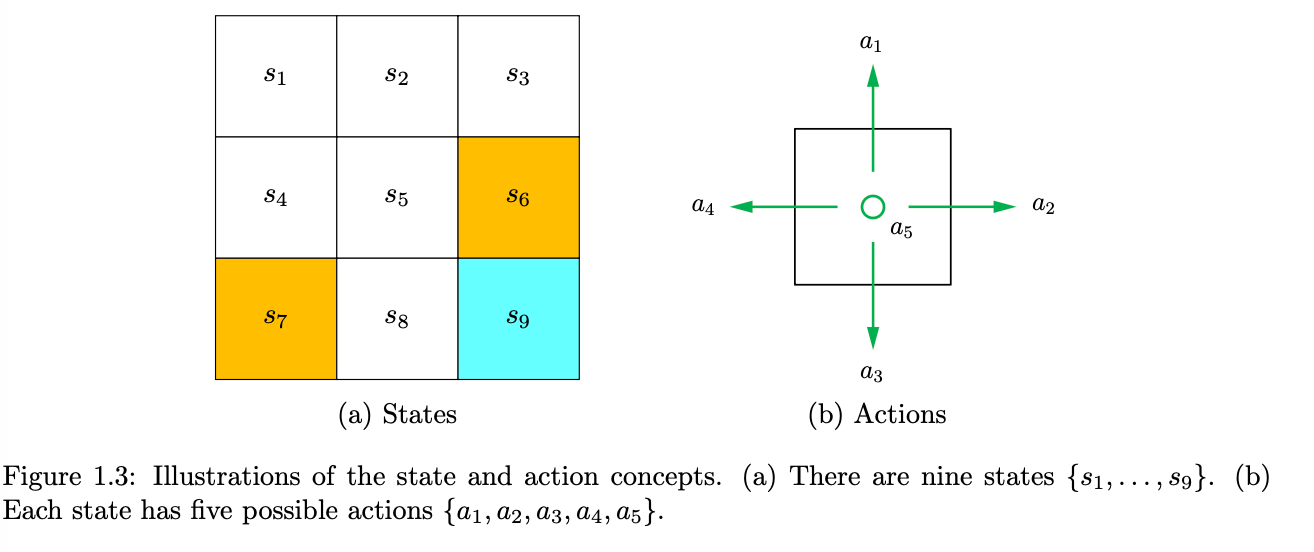
Grid and actionState 描述在特定环境中agent的状态,在上面的例子中,agent的状态就是他所处的格子位置,此时的state space就是$S={s_1, \cdots, s_9}$。对于每个状态,agent有5种可以采取的action(上下左右和保持不动),所有action的集合就是action space, $A = {a_1, \cdots, a_5}$(这里不同的状态可能会有不同的状态空间)。
State Transition
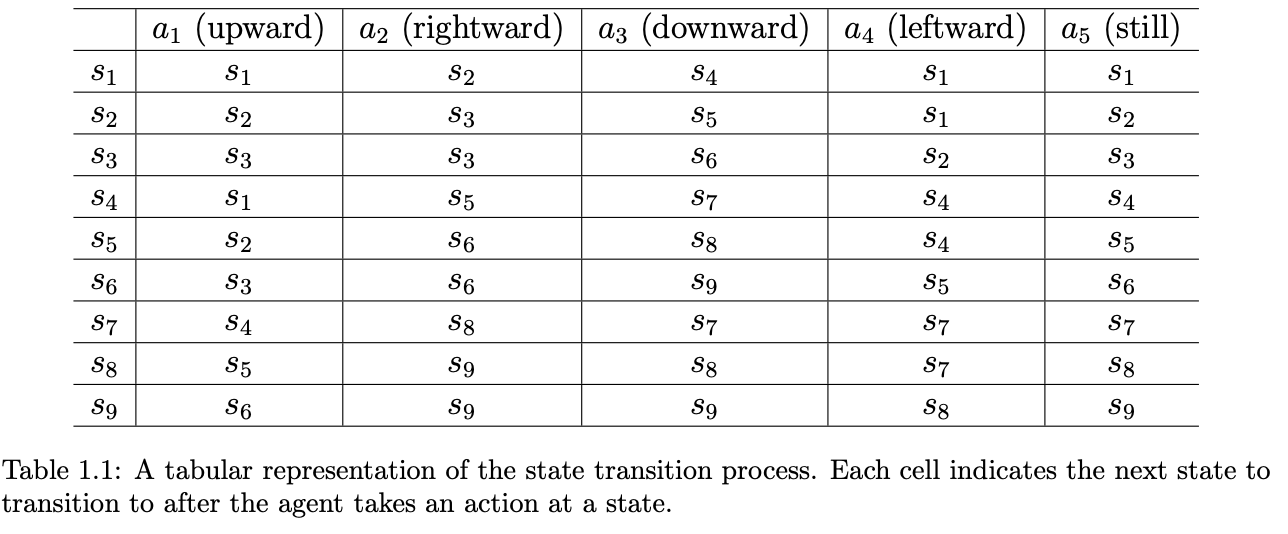
当采取action的时候,agent可能会从一个状态移动到另一个状态,这里过程就被称为 A tabular representation of the state transition processstate transition,像这样$s_1 \xrightarrow{a_2} s_2$。如果在状态$s_1$尝试采取$a_1$的时候因为会超出边界,所以被退回$s_1 \xrightarrow{a_1} s_1$;在状态$s_5$采取$a_2$的时候也会有两种可能,一种是直接可以到达$s_6$但是会被惩罚(这里惩罚对全局来说不一定是坏事,因为总体路径可能是最好的),另一种是直接不可到达$s_6$。下面这个表格给出了状态转移的过程,但是因为我们上面的分析都是确定性的,所以可以给出表格的形式,在一些随机的情况中可能就不是很适用了,这个时候可以采取条件概率这种形式。
$$
p(s_1 | s_1, a_2) = 0, \
p(s_2 | s_1, a_2) = 1, \
p(s_3 | s_1, a_2) = 0, \
p(s_4 | s_1, a_2) = 0, \
p(s_5 | s_1, a_2) = 0,
$$
Policy
Policy 告诉agent在每个状态应该采取的动作,有三种表示方式:
- 使用箭头表示在每个格子应该的动作
- 使用条件概率,$\pi(a | s)$
- 使用表格存储上面的条件概率
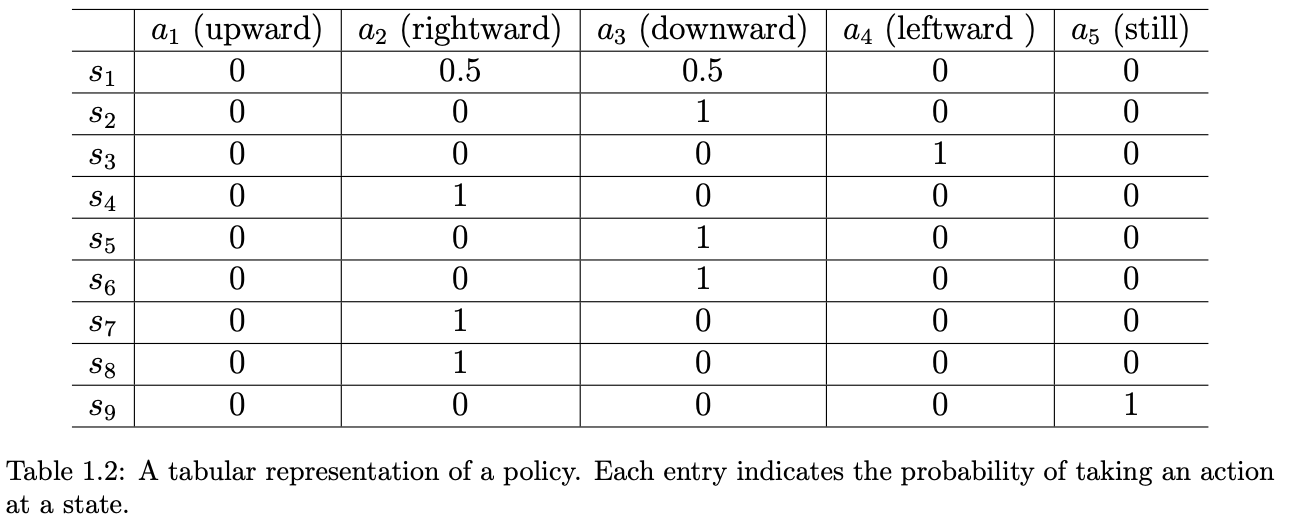
A tabular representation of a policy
Reward
当agent在某个状态执行了某个动作之后,他会从环境中得到一些反馈,这个就被称为reward,即$r(s,a)$。Reward值可以是正负和零,正的reward会鼓励agent采取特定的动作,负则会反对某些动作,零的话算是一种微弱的鼓励。在之前的格子示例中的Reward被设计为:
- 如果agent尝试越过边界,$reward_{boundary}=-1$
- 如果agent尝试进入forbidden,$reward_{forbid}=-1$
- 如果agent到达taget,$reward_{target}=+1$
- 其他情况下,$r_{other}=0$
Reward可以视作一种人机交互,通过他我们可以指导agent去做我们希望他做的一些事情,比如在上面例子中的避免超出边界和进入forbidden区域。同样的,我们可以把获取reward这个事情使用两个表示进行表达:表格(只能表示确定性的过程)和条件概率($p(r=-1|s_1,a_1) = 1, \ p(r\ne-1|s_1, a_1)=0$,此外获取某个reward也可以是随机的)。
A tabular representation of the process of obtaining rewards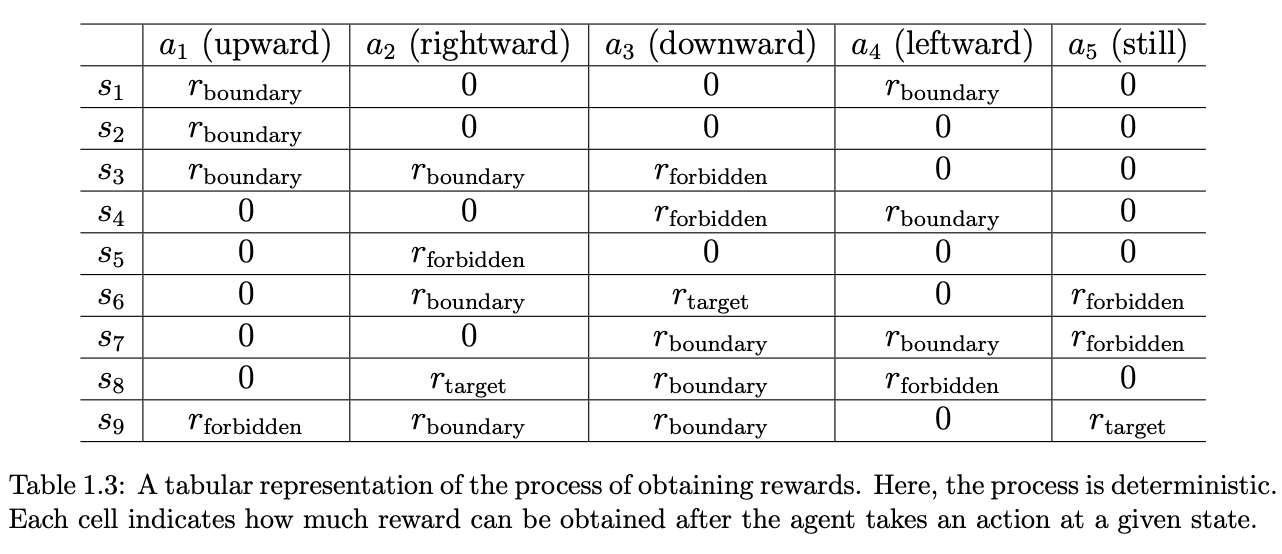
Trajectories, returns, and episodes
Trajectory 是一个 Trajectories obtained by following two policiesstate-action-reward链,这个链的return就是沿着这条路径的reward加和的结果,在下图里面,左侧图路径的return是1,右侧的return是0。
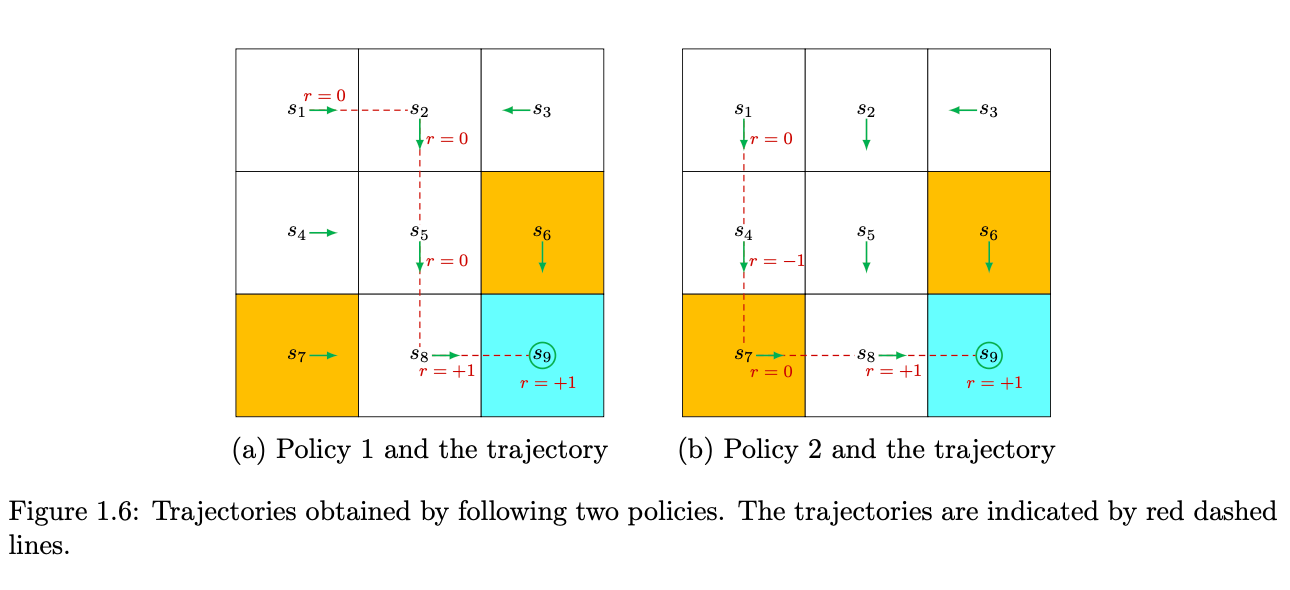
在上面的例子中是到达$s_9$这个状态就停止了,但是也很可能不停止,因为在$s_9$无论采取什么动作他的reward都是正的,所以这样策略下进行的trajectory的return是无穷大的。为了避免这种情况,可以因为discount factor $\gamma$,这样我们得到的return结果是: $$\text{discounted return} = 0 + \gamma 0 + \gamma^2 0 + \gamma^3 1 + \gamma^4 1 + \gamma^5 1 + \dots = \gamma^3\frac{1}{1-\gamma}, \gamma \in (0,1)$$ 引入这样一个因子可以带来两个好处:
- 不会出现无限长的trajectory了
- 可以用来调整是关注更近未来的reward还是更远未来的reward。当 $\gamma$ 接近于0的时候,后面的高次方项就非常小了,因此是关注更近的未来;当他的值接近于1的时候,agent就会关注更远的未来。
Episode 是指agent从初始状态开始,直到达到终止状态为止的一段完整的交互过程。这样的一个任务就被称为episodic task,他有着明确的开始点和结束点;相对应的是continuing task,他没有明确的结束,永无止境地进行。
Markov decision processes
随机过程是随时间变化的时间变量的集合,${X(t) | t \in T}$,马尔可夫性质是说某个时刻的状态只取决于上一个的时刻的状态,也就是$P(s_{t+1} | s_t) = P(s_{t+1} | s_t, s_{t-1}, \cdots, s_1)$,马尔可夫过程是具有马尔可夫性质的随机过程,也被称为马尔可夫链。给定一个马尔可夫过程,我们就可以从某个状态出发,根据它的状态转移矩阵生成一个状态序列(episode)。
马尔可夫过程示例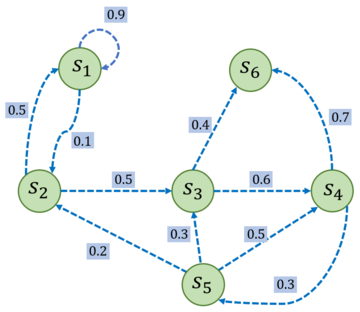
- Sets:
- 状态空间,所有状态的集合
- 动作空间,所有动作的集合,具体是个每个状态相关的
- 奖励集合,每个状态+动作对应得到的奖励,$R(s,a)$
- Model:
- 状态转移概率,在状态s,采取动作a转移到状态s’的概率是$p(s'|s,a)$
- reward概率,在状态s,采取动作a得到奖励r的概率是$p(r|s,a)$
- Policy:
- 在状态s,采取动作a的概率是$\pi(a|s)$
- Markov property:
- 历史无关的性质,$p(s_{t+1}|s_t, a_t, \cdots, s_1, a_1) = p(s_{t+1} | s_t, a_t)$